在最开始,先介绍一下这篇论文的来源。这篇文章发布于期刊《Pattern Recognition Letters》,在SCI分区中为三区期刊。上次组会时,据老师介绍,这个期刊虽然是三区期刊,但是对文章的创新性以及文章的篇幅页数要求很苛刻。这篇文章的作者是来自中山大学数据和计算机学院以及机器智能与先进计算教育部重点实验室的研究者。
原文链接:点这里
1. 摘要
作者在摘要里简要的介绍了自己方法的原理:". The clues for understanding facial expressions lie not in global facial appearance, but also in local informative dynamics among different but confusing expressions"。翻译的意思大体是:理解表情的线索不只在于整个面部的外观,也在于不同且复杂表情的局部信息动态。也就是说,作者的方法不只考虑了图片中整张人脸的外观信息,也考虑了人脸局部的动态信息(local informative dynamics)。
通过这样的一个构思,文章不仅构建了一个"Global Face Module"(全局面部模块,用来学习整个面部的空间信息特征),还引入了"Part-based Module"(基于部分的模块,用来学习面部关键部分的动态特征)。另外,在将训练数据送入到这两个模块进行训练之前,作者还使用了一个"Shared Shallow Module"进行面部低级特征的提取
最终,作者使用两个公开的基准面部数据集——CK+和Oulu-CASIA——进行方法验证。
2. 网络结构
下面是整个网络的结构,作者将它命名为"A multi-task global-local network(MGLN)":

从图上看,网络主要分为三个部分(就是刚刚在摘要中提到的三个):
-
SSM(Shared Shallow Module):SSM由一个在ImageNet上预训练的VGG16的前10层组成,它负责从全局和局部的面部区域中学习低级特征
-
GFM(Global Face Module):GFM是一个全卷积网络,负责提取表情峰值帧的整个面部表情的空间信息;
-
PBM (Part-based Module):PBM负责从图片序列中提取面部的局部动态变化特征。
对于网络的输入,在上图的最左侧,可以看到,网络的输入是一个图像序列。其中,上面的<Peak>表示当前序列的表情峰值帧(即序列中具有最大的表情强度的图片),它经过SSM处理后,提取到的特征被送入到GFM中进行表情空间特征的提取;下面的<Part Extraction>表示提取的面部关键位置(从上至下依次是眼睛、鼻子、嘴巴)的序列,为了避免过多的计算,作者简化了序列,提取一个序列中的首帧、中间帧以及峰值帧代表当前整个序列,这样,将三个区域的“序列”图片送入到SSM中提取特征后,送入到PBM中,提取局部信息动态特征。
(1) PBM
PBM的全称是:Part-Based Module,它由两个部分构成:A local spatio-temporal feature learning block(LST block)和Part end。输入是SSM产生的面部关键部分(眼睛、鼻子、嘴巴)的特征。
首先,它将来自SSM的空间特征首先使用几个卷积层进行处理,然后重构成一个1维的特征向量送入到LSTM中,从连续的帧中学习每一个面部关键部分的时间特征,最后,链接基于部分的特征:F_enm=[F_e;F_n;F_m ];随后,将连接后的特征F_enm送到Part end形成局部高级特征向量。
它的结构图如下所示,右侧是这一部分每层的构成及参数:


(2) GFM
GFM是一个全卷积网络,主要是通过表情峰值帧来提取当前表情图片的空间信息;它的输入是表情峰值帧经过SSM处理之后得到的低级特征。
它有两个改进:(1)在特征提取方面:在GFM中引入了可变卷积(Deformable convolutions),采样位置,能够更有效的提取表情特征;这种卷积方式能够调整和优化;(2)在分类阶阶段:GFM的最后一层卷积层的输出被设计为C(表情的类别数)个通道,使用了全局平均池化(GAP)从C个通道中直接计算分类分数。这样做的一个好处是GAP中没有参数,所以能够很好地避免过拟合。
它的结构图如下所示,右侧是这一部分每层的构成及参数:


(3) Module Fusing
在模块整合时,需要注意两个关键因素:(1)确保多样性信息结合时的互补性;(2)要采用合适的融合策略。
作者给出了自己的整合办法:(1)对于第一个因素:不同的训练输入和不同的网络架构能够产生表情表示多样性特征。对于训练输入,PBM使用局部关键区域作为输入,而GFM则考虑整张面部图片。对于网络架构,PBM使用LSTM来提取表情的动态特征,而GFM使用可变卷积来捕获静态空间外观; (2)对于第二个因素:对网络进行特征级别的整合以及决策级别的整合(如下所示)。
特征级别的整合就是在PBM中完成F_enm=[F_e;F_n;F_m ]的特征整合,其中F_e表示眼睛区域的特征,F_n表示鼻子区域的特征,F_m表示嘴巴区域的特征。
决策级别的整合就是在输出表情分类类别时,通过加权的方式融合PBM和GFM的输出,如下公式所示:
![]()
(4) 损失函数(交叉熵损失函数)
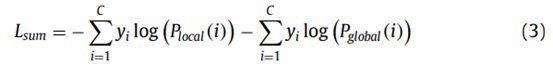
3. 总结(直接翻译过来的)
在这篇文章中,我们提出了一个多任务全局-局部网络来提取全局的空间特征和局部的细粒化特征用于表情识别。SSM学习全局和局部的低级外观特征。我们还提出了一个PBM,提取包括眼睛、鼻子、嘴巴在内的面部关键区域的时间细粒化特征。我们进一步提出了一个GFM来捕获与各种表情的全局空间配置相对应的互补特征。通过融合这两个模块,我们的网络能够通过学习局部-全局和时空信息来捕捉不同表情的变化。通过大量的实验,证明了该方法在CK+和Oulu-CASIA等公共基准数据集上具有良好的性能。
以上就是对这篇论文的笔记。