还记得鼎鼎大名的《Attention is All You Need》吗?不过我们今天要聊的重点不是transformer,而是注意力机制。
注意力机制最早应用于计算机视觉领域,后来也逐渐在NLP领域广泛应用,它克服了传统的神经网络的的一些局限,将有限的注意力集中在重点信息上,因而帮我们节省资源,快速获得最有效的信息。
同样作为热门研究方向,注意力机制近几年相关的论文数量自然是十分可观,我这次就整理了一系列关于PyTorch 代码实现注意力机制以及使用方法的论文。
本次分享Attention系列,共有30篇。有需要的同学看文末领取
Attention
1、Axial Attention in Multidimensional Transformers
一句话概括:Axial Transformers是一种基于自注意力的自动回归模型,它利用轴向注意力机制,在对高维张量数据建模的编码解码过程中,既保持了完全的分布表示能力,又大大减少了计算和存储需求,在多个生成建模基准上都取得了state-of-the-art的结果。
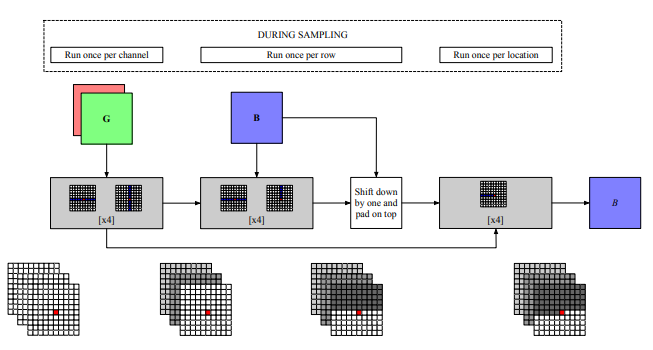
2、CCNet: Criss-Cross Attention for Semantic Segmentation
一句话概括:Criss-Cross网络利用criss-cross注意力和递归操作高效获取全图像依赖,在多个图像理解任务上达到state-of-the-art性能。
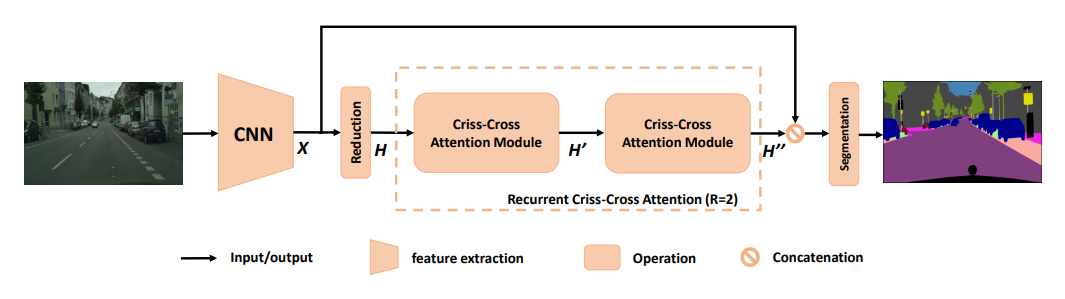
3、Aggregating Global Features into Local Vision Transformer
一句话概括:本文在局部窗口Transformer中引入了多分辨率重叠注意力模块聚合全局信息,找到了一种优化的架构设计,在多个图像分类数据集上优于之前的视觉Transformer。
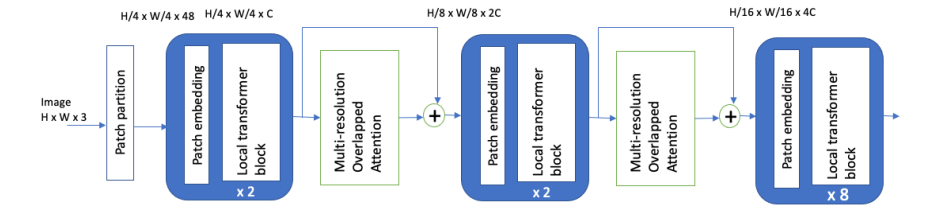
4、CROSSFORMER: A VERSATILE VISION TRANSFORMER HINGING ON CROSS-SCALE ATTENTION
一句话概括:本文提出了跨尺度嵌入层和长短距离注意力机制,实现了在vision transformer中跨尺度特征的提取和互作用。这不仅减少了计算量,还在嵌入中保留了小尺度和大尺度的特征。基于此,构建了一个通用的计算机视觉架构CrossFormer,可以处理不同尺寸的输入。在多个视觉任务上优于其他视觉transformer。
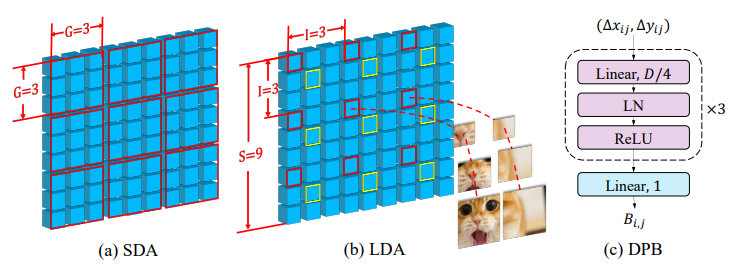
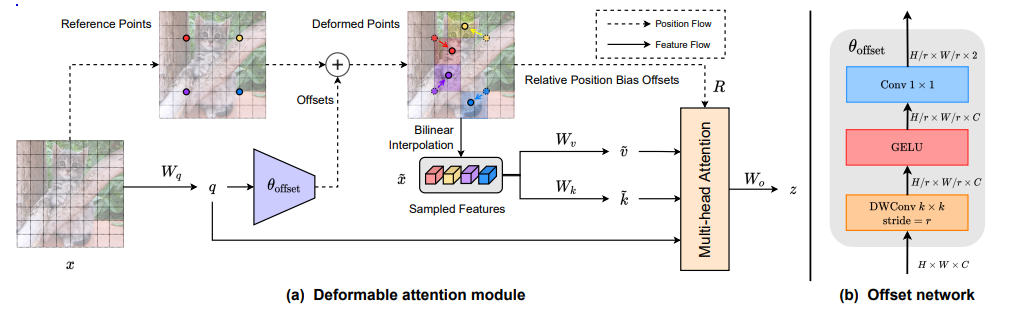
5、Vision Transformer with Deformable Attention
一句话概括:本文提出了可变形的自注意力模块和基于其的可变形注意力Transformer,通过数据依赖方式选择键值对位置,使注意力机制能够关注相关区域,在图像分类和密集预测任务上优于已有方法。
6、Separable Self-attention for Mobile Vision Transformers
一句话概括:本文提出了一个线性复杂度的可分离自注意力机制,使用逐元素操作计算自注意力,大大降低了移动设备上vision transformer的延迟。基于此的模型MobileViTv2在多个移动视觉任务上达到state-of-the-art性能,计算速度比MobileViT提升3.2倍。

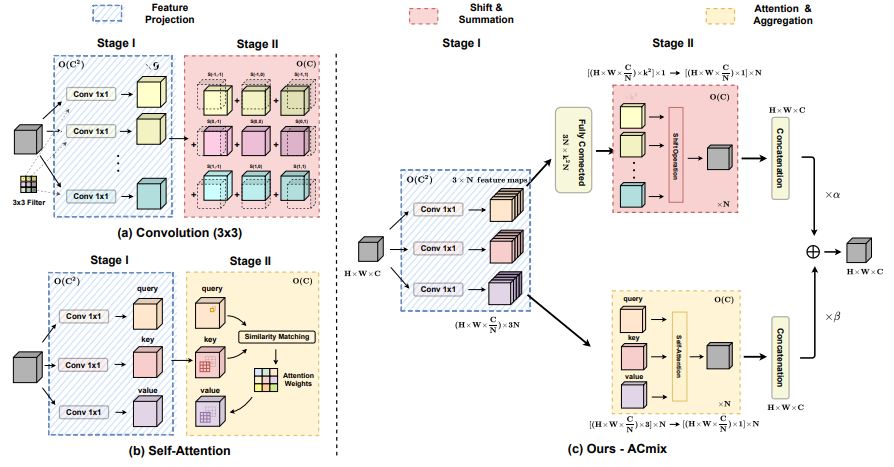
7、On the Integration of Self-Attention and Convolution
一句话概括:本文提出卷积和自注意力在计算上存在内在联系,都可分解为多个1x1卷积加上移位和求和操作。基于此,提出了一种混合模块ACmix,融合了卷积和自注意力的优点,计算量也较单独使用两者更低。在图像识别和下游任务上取得了state-of-the-art的结果。
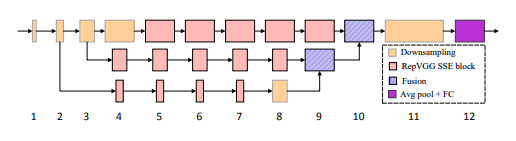
8、Non-deep Networks
一句话概括:本文通过采用并行子网络结构代替层层堆叠,构建了深度仅为12层的“非深度”神经网络,在多个视觉任务上都获得了state-of-the-art的性能,为构建低延迟的识别系统提供了新的思路。
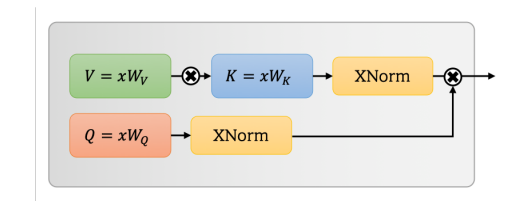
9、UFO-ViT: High Performance Linear Vision Transformer without Softmax
一句话概括:本文提出了一个计算复杂度线性的自注意力机制Unit Force Operated Vision Transformer (UFO-ViT),通过消除原始自注意力中的非线性,将矩阵乘法分解为线性操作,仅修改了自注意力的少量代码。该模型在图像分类和密集预测任务上,在大多数模型容量下都优于基于transformer的模型。
10、Coordinate Attention for Efficient Mobile Network Design
一句话概括:本文提出了坐标注意力机制,通过将位置信息融入通道注意力,生成方向感知和位置敏感的注意力图,增强移动网络在图像分类和下游任务中的表现,计算量几乎没有增加。

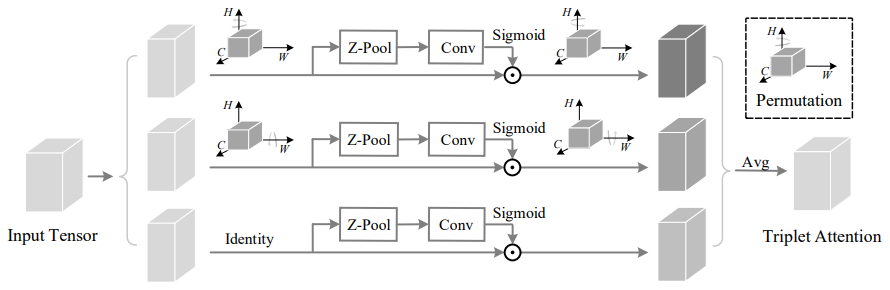
11、Rotate to Attend: Convolutional Triplet Attention Module
一句话概括:本文提出了三元组注意力机制,通过三分支结构以很小的计算量编码跨维信息,作为附加模块植入骨干网络,在图像分类和目标检测任务上取得了效果。
12、Global Filter Networks for Image Classification
一句话概括:本文提出了全局滤波网络GFNet,通过频域全局滤波的方式以对数线性复杂度学习长程空间依赖,作为transformer和CNN的一种高效、泛化强且稳健的替代方案。

13、S22-MLPv2: Improved Spatial-Shift MLP Architecture for Vision
一句话概括:本文提出了改进的空间移位MLP网络S2-MLPv2,采用通道扩展和特征图拆分,以及金字塔结构和更小尺寸的patch,在ImageNet上取得83.6%的top-1准确率。

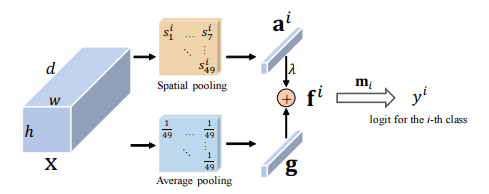
14、Residual Attention: A Simple but Effective Method for Multi-Label Recognition
一句话概括:本文提出了一个极简的模块类特定残差注意力(CSRA),用于多标签图像识别。CSRA通过生成类别特定的空间注意力分数,获得每个类别的特定特征表示,并与类别不可知的平均池化特征组合。CSRA实现了多标签识别的state-of-the-art结果,且比现有方法简单许多。
15、Contextual Transformer Networks for Visual Recognition
一句话概括:本文提出了Contextual Transformer模块,通过邻近键的上下文编码指导注意力矩阵学习,增强了视觉表示能力,可直接替换ResNet中的3x3卷积,形成更强大的Transformer骨干网络。

16、Polarized Self-Attention: Towards High-quality Pixel-wise Regression
一句话概括:本文提出了极化自注意力模块,通过极化过滤和输出分布增强设计,实现了高质量的像素级回归,在多个基准测试中显著提升了姿态估计和语义分割的性能。

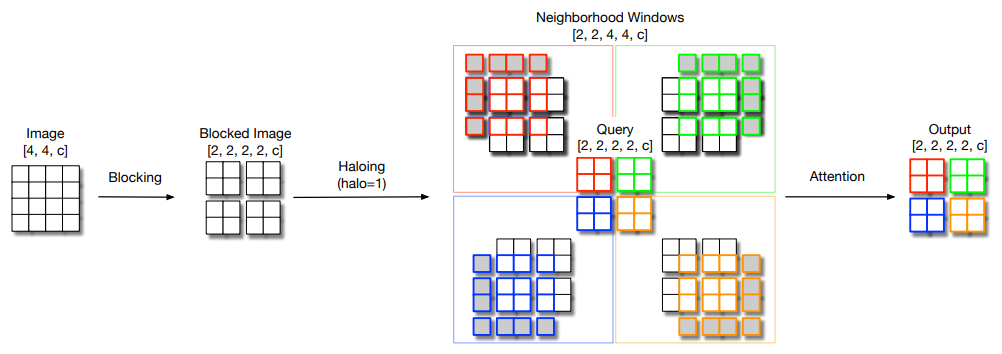
17、Scaling Local Self-Attention for Parameter Efficient Visual Backbones
一句话概括:本文通过自注意力的两种扩展和更高效实现,提出了HaloNet模型系列,在参数受限的ImageNet分类中达到state-of-the-art精度,并在目标检测和实例分割等任务上优于传统卷积模型。
18、CoAtNet: Marrying Convolution and Attention for All Data Sizes
一句话概括:本文提出了CoAtNet,一种混合卷积和自注意力的模型家族,通过两点洞见有效结合了两种架构的优势:(1)深度可分卷积和自注意力可通过相对注意力自然统一;(2)原则性地垂直堆叠卷积和注意力层可以惊人地改善推广性、容量和效率。实验表明,在不同的数据集和资源约束下,CoAtNet都达到了state-of-the-art性能。
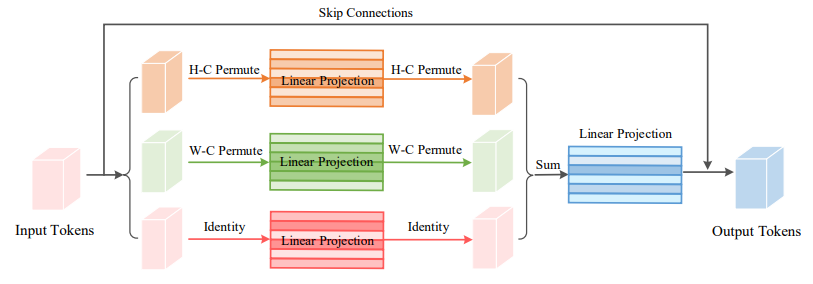
19、Vision Permutator: A Permutable MLP-Like Architecture for Visual Recognition
一句话概括:本文提出了Vision Permutator,一个概念简单且数据效率高的类MLP架构,用于视觉识别。它通过在高度和宽度维度上分别对特征编码,捕获一个空间维度的长程依赖,同时在另一个维度上保留精确的位置信息。这样的位置敏感输出以互补的方式聚合,形成对目标的表达性表示。在不依赖空间卷积或注意力机制的情况下,Vision Permutator在ImageNet上达到81.5%的top-1准确率,使用2500万参数明显优于大多数CNN和transformer。
20、VOLO: Vision Outlooker for Visual Recognition
一句话概括:本文提出了Vision Outlooker (VOLO),一个简单通用的基于注意力的模型架构,在ImageNet图像分类任务上首次无需额外训练数据即超过87%的top-1准确率。VOLO中的outlook注意力机制高效地将细粒度的特征和上下文编码到tokens中,这对识别性能至关重要但自注意力机制缺乏。
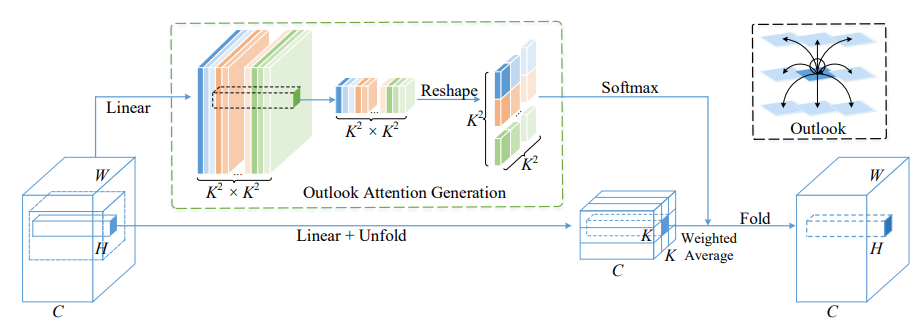
21、An Attention Free Transformer
一句话概括:本文提出了Attention Free Transformer (AFT),一种高效的Transformer变体,消除了点积自注意力的需要。在AFT层中,键和值先与一组学习到的位置偏置组合,结果与查询按元素相乘。这种新操作的内存复杂度对上下文大小和特征维度均是线性的,兼容大规模输入和模型大小。文中还提出了AFT-local和AFT-conv两种变体,利用局部性思想和空间权重共享的同时保持全局连接。在两个自回归建模任务(CIFAR10和Enwik8)和图像识别任务(ImageNet分类)上的大量实验表明,AFT在保持高效率的同时达到了竞争性能。
22、A2 -Nets: Double Attention Networks
一句话概括:本文提出“双注意力模块”,通过双重注意力机制高效聚集和传播整个输入时空的全局信息,使卷积网络能有效访问全部特征,从而增强图像和视频的长程依赖建模能力。该模块首先通过二阶注意力池化将全部特征聚集到一个紧凑集,然后自适应地分发特征到每个位置。
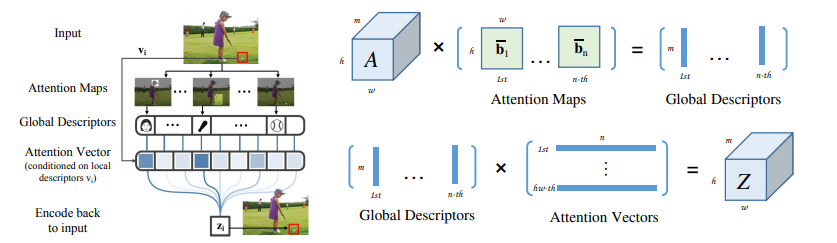
23、Spatial Group-wise Enhance: Improving Semantic Feature Learning in Convolutional Networks
一句话概括:CNN通过分层收集不同语义子特征来生成复杂对象的特征表达,这些子特征通常以组的形式分布在各层特征向量中,表示不同语义实体。为校正背景噪声对子特征激活的空间影响,文中提出了空间组别增强(SGE)模块,通过每个语义组在各空间位置生成注意力因子来调节每个子特征的重要性,使各组可自主增强学习表达和抑制噪声。
24、MUSE: Parallel Multi-Scale Attention for Sequence to Sequence Learning
一句话概括:本文探索了在序列数据上进行并行多尺度表示学习,旨在同时捕获长程和短程语言结构。为此,提出了并行多尺度注意力(MUSE)和MUSE-simple。MUSE-simple包含了并行多尺度序列表示学习的基本思想,它使用自注意力和逐点变换并行地以不同尺度编码序列。MUSE在MUSE-simple的基础上,结合卷积和自注意力从更多不同尺度学习序列表示。

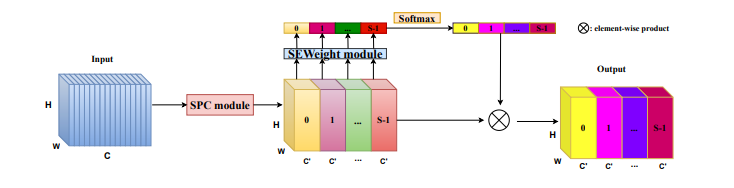
25、SA-NET: SHUFFLE ATTENTION FOR DEEP CONVOLUTIONAL NEURAL NETWORKS
一句话概括:本文提出了高效的洗牌注意力(SA)模块,采用洗牌单元有效结合了空间注意力和通道注意力机制。具体来说,SA先将通道维度分组成多个子特征进行并行处理。然后,对每个子特征使用洗牌单元同时建模空间和通道维度之间的依赖关系。最后,聚合所有子特征并采用“通道洗牌”操作者促进不同子特征之间的信息交流。

26、ResT: An Efficient Transformer for Visual Recognition
一句话概括:本文提出了一个高效的多尺度视觉Transformer,名为ResT,它可以作为通用的图像识别骨干网络。与现有的Transformer方法不同,ResT具有以下几个优点:1. 构建了高效的多头自注意力,通过简单的逐点卷积来压缩内存,并在保持多头注意力多样性的同时,实现头维度间的交互。2. 将位置编码构建为空间注意力,更加灵活,可以处理任意大小的输入图像,无需插值或微调。3. 在每个阶段开始时,没有进行直接的标记化,而是将patch嵌入设计为具有步幅的重叠卷积操作的堆叠。
27、EPSANet: An Efficient Pyramid Squeeze Attention Block on Convolutional Neural Network
一句话概括:本文提出了一种称为金字塔压缩注意力(PSA)的轻量级有效的注意力机制。通过在ResNet瓶颈块中用PSA模块替换3x3卷积,得到一种称为有效金字塔压缩注意力(EPSA)的新表示块。EPSA块可以轻松地作为即插即用组件添加到成熟的backbone网络中,并显著提高模型性能。
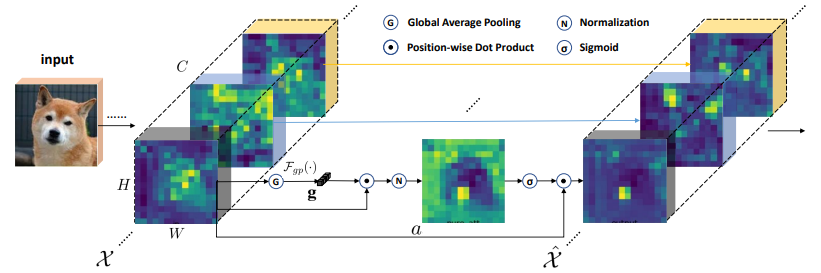
28、Dual Attention Network for Scene Segmentation
一句话概括:本文通过自注意力机制捕获丰富的上下文依赖关系来解决场景分割任务。与之前通过多尺度特征融合来捕获上下文的工作不同,本文提出了双注意力网络DANet,可以自适应地整合局部特征及其全局依赖关系。

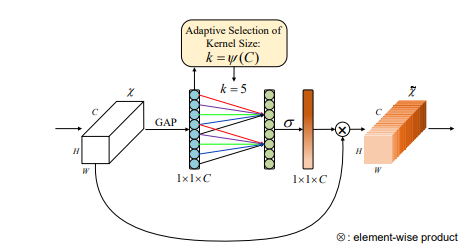
29、ECA-Net: Efficient Channel Attention for Deep Convolutional Neural Networks
一句话概括:本文提出了一个高效的通道注意力(ECA)模块,只涉及极少的参数量,但带来了明显的性能提升。通过剖析SENet中的通道注意力模块,我们经验证明避免降维对学习通道注意力非常重要,适当的跨通道交互可以在显著降低模型复杂度的同时保持性能。因此,我们提出了一个没有降维的局部跨通道交互策略,可以通过1D卷积高效实现。此外,我们开发了一种自适应选择1D卷积核大小的方法,确定局部跨通道交互的范围。
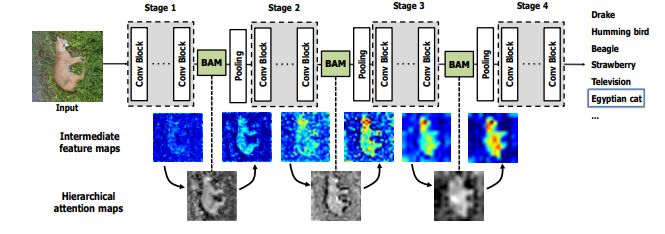
30、BAM: Bottleneck Attention Module
一句话概括:本文提出了一个简单有效的注意力模块,称为瓶颈注意力模块(BAM),可以与任何前馈卷积神经网络集成。该模块沿着通道和空间两个独立路径推断注意力图。我们在模型的各个瓶颈放置该模块,即特征图下采样的位置。该模块在瓶颈构建了层次化的注意力,参数量少,可以与任何前馈模型端到端训练。
关注下方《学姐带你玩AI》🚀🚀🚀
码字不易,欢迎大家点赞评论收藏!