论文地址:Language Models are Unsupervised Multitask Learners
上篇:GPT-1论文要点解读

在上篇:GPT-1论文要点解读中我们介绍了GPT1论文中的相关要点内容,其实自GPT模型诞生以来,其核心模型架构基本没有太大的改变,都是一路坚持奉行着基于Transformer的单解码器结构,通过无监督预训练方式来拟合条件概率下的语言模型计算公式,通过利用任务相关的输入样本对预训练模型进行有监督微调,从而满足一个模型cover多任务的需求。结构上,GPT-2并没有做太大的改变,但是GPT-2可以说是一个重要的转折节点,具有承上启下的“历史意义”(说大了),自GPT-2之后,GPT系列的模型就不再开源,也没有相应的论文,只有一些长篇技术报告,比较头疼。不管了,先来看下GPT-2主要讲了些什么吧!
Abstract

这是摘要中值得注意的第一个点,作者提到,当他们在一个新的数据集(WebText)上训练GPT时,发现了语言模型能够在没有明确监督的情况下就具有学习不同任务的能力,这个发现可以说是非常之重要了,我比较好奇的是,为啥其它机构的大佬没有发现?

这是第二个值得关注的地方,作者提到了一个目前看来很正确的结论,那就是模型的容量对于零样本任务迁移的成功以及模型的性能至关重要。作者举了个例子,它们的GPT-2拥有15亿个参数,所以在8个测试数据集中有7个测试取得了SOTA的结果。

此外,作者说它们观察了这些模型生成的文本后,发现这些文本的连贯性很好,于是作者们认为这表明了语言模型可以通过观察和学习这些自然发生的示例来学习执行不同的任务,而无需明确的监督指导,说白了,就是模型完全能从自然文本中学习到不同的任务类型,不需要针对不同任务设计不同的微调标注样本。
1. Introduction
这部分没有太多核心内容,主要就是介绍了一些现有的研究方法,但作者通过该章节,突出强调了现有语言模型的通用性和鲁棒性差。我们看下开头:


作者在开头就提到了当前的语言模型非常依赖于标注数据,因此也容易收到数据样本微小分布差异的影响,作者称这样的模型精而不博,不是个“多面手”。所以最后作者提到他们正在将工作重点转移到能够承担起多个任务的模型研发中,这种模型(GPT2)不需要为每个任务都去人工标注差异化训练数据。作者也在下面这段话中表达了一种怀疑:

作者怀疑在单一领域数据集上进行单一任务训练可能是当前系统缺乏泛化能力的主要原因。而为了实现具有鲁棒性的系统,可能需要在各种领域和任务上进行训练和性能评估。说实话,个人认为这篇论文空话比较多,各种表明各种证实,但基本上都是基于一些针对现象的猜测,有种“马后炮”的既视感,严重怀疑作者们并没有把核心干货介绍出来==。

这段话指出,尽管多任务学习在提高性能方面具有潜力,但在NLP领域,多任务训练仍处于初级阶段。这也是作者们开发GPT2的动机,其实包括后面的chatGPT也是由这种动机演变而来的。作者认为当前的机器学习系统需要靠成百上千个样例的学习才能生成良好的泛华函数,于是作者认为对于多任务的学习,应该同样需要不同任务下的大量的样例学习,这在资源匮乏的情况下是很难做到的(凡尔赛,毕竟chatGPT也是靠巨量数据集和人力资源堆叠出来的),所以作者产生了探索其它多任务学习方法的动机。

作者在最后说,他们结合了两条路线来进行研究,个人理解两条路线指的是无监督和有监督两种。作者主要在说明零样本学习的对于多任务学习的迁移能力。
此外,作者提供了一个图比较有意思,我们来看一下:

横坐标代表模型的大小,这里作者主要发布了4种不同大小的GPT模型,从图中可以看出,随着模型容量的增长,其模型性能也会有所提升,上图中,在阅读理解、翻译、问答任务中都表现得不错,只有在摘要生成任务上和Seq2Seq+Attention对比貌似还差点意思, 但是从这个图中也可以看出,随着模型参数量的增大,模型的性能仍然有上升空间的潜力,这也正是GPT-3要干的事。
2. Approach
这一章作者介绍了自己的研究方法。开头作者主要介绍了语言模型的范式表达,即语言模型是对条件概率的表达。对于这样一种表达,近年来有一些重要的改进,例如引入注意力机制,特别是自注意力机制的Transformer。

接下来这段话有个很重要的地方值得关注,作者说,由于生成模型应该具备执行多任务的能力,因此条件概率中的条件必须包含着任务属性,即(input,task),这也成为了后来大家都在用的指示学习的方式。作者提到,语言本身就能够灵活的表达特定的任务,这说明我们能够灵活的调整输入输出的的表达即可让模型完成不同任务的学习,在GPT-1中,主要还是利用一些模型没见过的分隔符来区分不同的输入,但在GPT-2中作者认为,为了让模型能够适用于不同的任务,最好的方法就是去掉未知分隔符,完全用自然语言来代替分隔符,比如作者举例,要让模型完成翻译任务,输入可以是直接”告诉“模型:将英语翻译成法语,后接英文文本,法语文本(目标文本)。不得不说,作者们的思路确实很精妙!事实证明,通过引入Prompt的学习,能让模型的性能和鲁棒性有很大的提升。

语言模型原则上也能够学习McCann等人(2018年)提出的任务,而无需明确指定哪些符号是要预测的输出,看了下这个任务,是多任务问答任务,无需明确指定哪些符号是要预测的输出指的是无约束性的输出。作者又臆想了,但也好有道理:由于监督目标与无监督目标相同,只是在序列的子集上进行评估,因此无监督目标的全局最小值也是监督目标的全局最小值,那么既然如此,何不在无监督学习上做文章呢?所以问题就转变成了能否优化无监督的目标函数使其收敛。作者的初步实验证实,足够大的语言模型能够在这种玩具化的设置中进行多任务学习,但学习速度比明确监督的方法要慢得多。

作者通过对话任务的分析推测,具有足够容量的语言模型将开始学习推断和执行自然语言序列中所展示的任务,以更好地预测它们,而不管模型是通过什么方式来达到这一效果的。
2.1 Training Dataset
这一小节就是让大家了解一下GPT2的训练集。

作者立志要构建一个高质量的、多领域、多任务的大数据集,所以作者们构建了吗?显然是构建了,而且数据量非常庞大,质量不敢说非常高吧,但肯定不赖,不然chatGPT怎么来的?

作者之所以不满意于现有的数据集,因为他们发现类似于Common Crawl这样著名的互联网大数据集有很多数据质量问题,所以下面作者说:

作者们提出了一种新的网络爬取方法,这种爬虫方法强调文档质量。为了实现这一点,他们只爬取了经过人工精心筛选/过滤的网页。由于手动筛选整个网络进行爬取成本太高,所以他们从Reddit这个社交媒体平台上爬取了所有至少获得3个karma(所以karma是啥?我感觉类似于转评赞的综合得分这样的东西)的外部链接,这可以被视为其他用户是否发现链接有趣、有教育意义或仅仅是有趣的启发式指标。

作者创建的数据集名为WebText,论文中呈现的所有结果都使用了WebText的初级版本,该版本不包括2017年12月之后创建的链接,并且经过去重和一些基于启发式的数据清洗工作,共包含了800多万个文档,大小约40 GB。此外,作者们从WebText中删除了所有的维基百科文档,因为它是其它数据集的常见数据源,作者怕有重合,导致后期模型的评估出现偏差。
2.2 Input Representation
这部分主要介绍了一下GPT-2的输入表示。作者提到了一种字节对编码(Byte Pair Encoding,简称BPE)方法,通常该方法的实现通常操作的是Unicode代码点而不是字节序列,这些实现需要包括完整的Unicode符号空间以建模所有的Unicode字符串,但这将导致基本词汇量超过130,000,作者认为这太荒谬了,但如果以字节级别的方式建模,又容易造成次优的合并,什么是次优合并?作者举了个例子:比如dog,因为它们以多种变体出现,比如dog. dog! dog?,这导致了有限词汇槽和模型容量的次优分配,也就是说同一个单词可能会和一些跨类别的字符进行合并,为啥呢?因为BPE使用贪婪的基于词频的启发式方法来构建标记词汇。那么为了避免出现这种情况,作者禁止BPE在任何字节序列中跨字符类别进行合并,但是空格例外,因为英文中,单词和单词之间是用空格隔开的,这天然支持了空格和单词的这种合并。
2.3 Model
这一节描述了GPT-2的模型细节,比较重要,奈何作者只用了一段话。。。


仔细分析起来,其实也没啥新鲜的,总的来说,GPT-2有以下几个特点:
- 沿用了transformer结构,不出意料,还是只有编码器;
- Layer normalization移动到每个子块的输入处;
- 自注意力层和未经过激活函数的残差输出之后也添加了一层Layer normalization;
- 在初始化时,通过将残差层的权重缩放因子设置为1/√N(其中N是残差层的数量),来进行初始化;
- 词汇量扩展到50,257;
- 将上下文大小从512扩展到1024个Token,并在本文中使用了更大的512个batchsize;
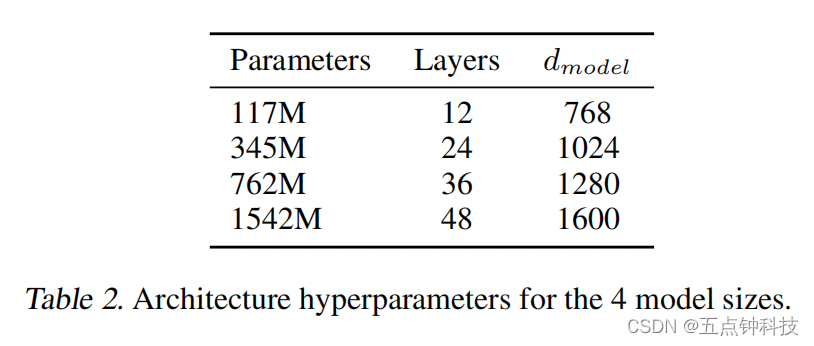
这个图展示了作者发布的4种不同大小的GPT模型对应的层数以及维度。自此,大模型一发不可收拾。。。
3. Experiments
这一章就是实验部分了,没啥可介绍的,感兴趣的小伙伴可以自行阅读。这里挑几个比较有意思的地方说一下:
3.3 LAMBADA


作者通过观察GPT-2预测错误的地方发现,大多数错误的句子都是有效的连贯句,但是都没有有效的结束词,这表明了语言模型没有使用额外的有用的限制来规定某个词必须是句子的结尾。在最后,作者还得出了一个结论:对于GPT-2来说,约束性生成的限制并不合适,换句话将,GPT-2可能并不适合用来做约束性受控文本生成任务。其实在我实际的实验中,也发现它在这方面的表现没有比开放性文本生成好。猜测可能根GPT-2在未发生涌现能力之前,单解码器结构本身的特性有关。对比编解码器结构的T5,它在约束性文本生成任务中表现的就不错。
3.8 Question Answering

作者通过这一节的实验又一次提到了模型容量的重要性,的确,目前已经证实了,在一定范围内,模型参数量的大小能够促使模型发生涌现能力。
4. Generalization vs Memorization
这一章主要讨论了关于语言模型的泛化能力和记忆能力的问题。作者指出,语言模型在阅读理解任务中的表现仍然远远落后于结合信息检索和提取式文档问答的开放领域问答系统。作者还提到,一个自称对随机琐事很擅长的人在与GPT-2在相同环境下进行测试时,只有17%的问题回答正确。此外,作者还讨论了语言模型在摘要生成和翻译任务中的表现,并指出GPT-2在这些任务中的性能仍然有待提高。最后,作者提出了对语言模型在各种任务中的性能进行零样本测试的方法,并探讨了语言模型在自然语言序列中学习和执行任务的能力。
5. Related Work
这一章针对生成式语言模型做了一些别人家的相关工作的介绍。
6. Discussion
这一章主要讨论了GPT-2在零样本使用上对于多任务学习的成功和不足,以及继续探索它的价值潜力,还提到了在增加额外训练集和模型容量上是否足以克服BERT在单向表征上的不足仍然需要继续研究。
7. Conclusion
总结没啥说的,我直接翻译了:当一个大语言模型在足够大且多样化的数据集上进行训练时,它能够在许多领域和数据集上表现的出色。GPT-2在8个测试的语言建模数据集中有7个达到了最先进的性能。模型在零样本设置下能够执行任务的多样性表明,容量高的模型在足够大且多样化的文本语料库的训练时将开始学习如何执行令人惊讶的多个任务,而无需在本文中进行明确的监督。
总的来说,大家在读完这篇论文后会发现比较空洞,能提取到有价值的干货并不多,但是确实可以洞见GPT作者们深邃的思考,这一点是值得我们学习的。另外提一嘴,GPT-1是先于BERT提出的,所以在当时看来,其思想是很有新意的,它打破了传统自然语言处理的范式,但后来更大参数量的编解码结构的BERT出现后,刷新了GPT-1的记录,因此也就诞生了对标BERT的GPT-2,其核心亮点就是Zero-shot。







