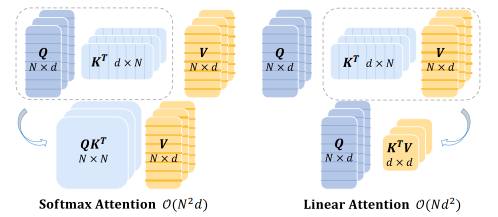
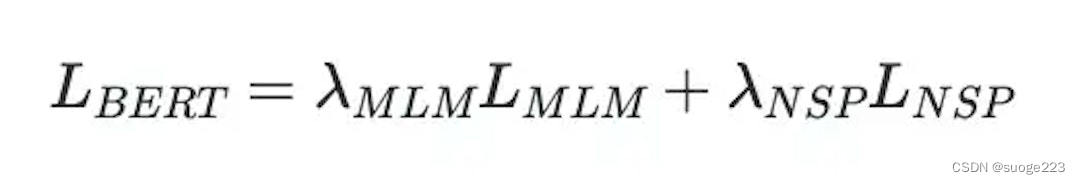线性注意力机制通过对传统注意力机制中的Softmax操作进行线性化处理,可以提高Transformer模型的并行性能、降低复杂度,在计算效率、模型表达能力等方面都具有优势。
作为一种常用有效的优化方法,线性注意力机制可以在保证模型性能的同时提高计算效率。而近期,有关线性注意力机制的研究有了新的成果,其中最具代表的就是代理注意力、TransNormerLLM。
-
Agent Attention:Softmax注意力与线性注意力的结合,创造了一种既高效又强大的新型注意力机制。这种结合体现在所谓的“代理注意力”中,它通过两个常规的Softmax注意力操作的组合,实现了高性能和高效率的融合。
-
TransNormerLLM:第一个基于线性注意力的大模型,完全抛弃了基于 Softmax 的注意力机制,而是使用了新提出的线性注意力。
除以上两种创新以外,还有一些值得关注的线性注意力机制相关成果,都是前沿最新,我也帮同学们列出了部分成果的方法和创新点,大家可以借鉴学习,目前共有9篇,附上开源代码方便复现。
论文以及开源代码需要的同学看文末
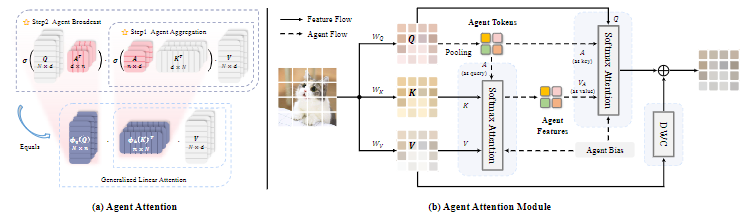
Agent Attention
Agent Attention: On the Integration of Softmax and Linear Attention
方法:论文提出了一种新颖的注意力机制,Agent Attention,用于在计算效率和表示能力之间取得良好的平衡。Agent Attention引入了一组额外的代理令牌A到传统的注意力模块中,通过代理令牌A从键K和值V中聚合信息,并将信息广播回查询令牌Q。Agent Attention可以显著提高计算效率,同时保持全局上下文建模能力。
创新点:
-
作者引入了一种新的注意力范式,称为Agent Attention,它是一种高效的注意力机制,能够在计算效率和表示能力之间取得良好的平衡。
-
Agent Attention通过引入额外的代理令牌,将传统的Softmax注意力与线性注意力无缝集成,既具有高表达能力又具有低计算复杂度。
-
通过在各种视觉Transformer模型和不同的视觉任务中进行广泛实验证明了Agent Attention的有效性,特别是在高分辨率场景下。
-
Agent Attention还可以直接应用于预训练的大规模扩散模型,加速图像生成过程并显著提高生成质量。
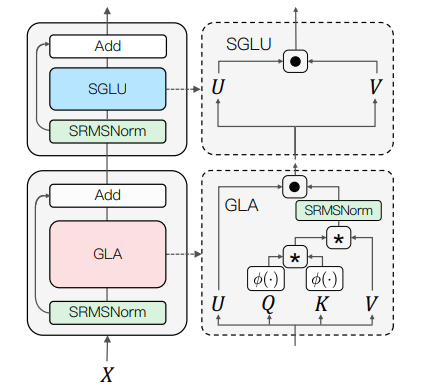
TransNormerLLM
TransNormerLLM: A Faster and Better Large Language Model with Improved TransNormer
方法:论文介绍了一种改进的TransNormer模型——TransNormerLLM,该模型在准确性和效率方面均优于传统的Transformer模型。作者还提出了一种原始推理算法,并对GLA结构的激活函数进行了实验。此外,作者还对模型并行性和系统优化技术进行了评估,包括它们对训练速度和上下文长度的影响。
创新点:
-
TransNormerLLM是一种改进的TransNormer,专为LLMs定制。
-
TransNormerLLM在准确性和效率方面始终优于Transformers。
-
TransNormerLLM在位置编码、门控机制、激活函数、归一化函数和闪电注意力方面进行了修改和创新,这些修改共同促成了TransNormerLLM的出色性能,使其成为最先进语言模型的有希望选择。
-
TransNormerLLM的基准结果表明,具有3.85亿、10亿和70亿参数的模型不仅与当前领先的基于Transformer的大型语言模型的性能相匹配,而且具有更快的推理速度。
其他创新方法
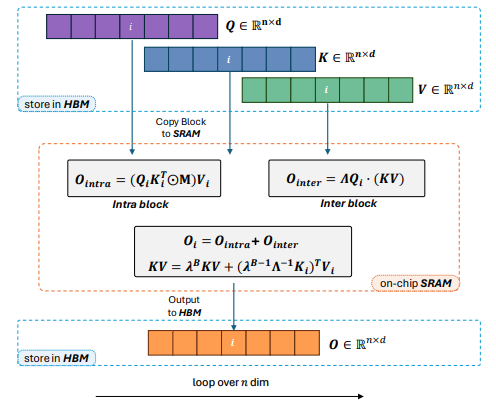
Lightning Attention-2: A Free Lunch for Handling Unlimited Sequence Lengths in Large Language Models
方法:论文提出了Lightning Attention-2,这是第一个能够实现线性注意力的理论计算优势的线性注意力实现。为了实现这一目标,作者采用了切分和平铺技术的思想,分别处理线性注意力计算中的内部块和间隔块组件。具体而言,作者利用传统的注意力计算机制处理内部块,并对间隔块应用线性注意力核技巧。通过前向和后向过程中的平铺技术,充分利用GPU硬件的优势。
创新点:
-
Lightning Attention-2在计算速度上具有显著优势,这归功于其创新的内部-外部分离策略。
-
Lightning Attention-2相比其他机制具有更小的内存占用,而不会影响性能。
FLatten Transformer: Vision Transformer using Focused Linear Attention
方法:论文提出了一种新颖的聚焦线性注意力模块。通过从关注能力和特征多样性的角度解决以前线性注意力方法的局限性,作者的模块实现了高效性和表达能力的令人印象深刻的结合。在图像分类、目标检测和语义分割等广泛实验中,作者的模块可以广泛应用于各种视觉Transformer,并在计算效率和模型性能之间取得更好的平衡。
创新点:
-
Focused Linear Attention:通过对线性注意力的性能下降进行了详细分析,从关注能力和特征多样性两个方面提出了改进方法,解决了线性注意力的性能问题,实现了高效性和表达能力。
-
Vision Transformer:在计算机视觉领域引入了Transformer和自注意机制,但由于计算复杂度高,直接应用于视觉任务存在困难。先前的研究从多个角度尝试解决这个问题,如减少输入分辨率、采用稀疏注意力模式、逐渐降低特征分辨率等。这些方法在一定程度上解决了计算复杂度的问题,但仍存在一些限制。
关注下方《学姐带你玩AI》🚀🚀🚀
回复“线性注意力”获取论文+代码
码字不易,欢迎大家点赞评论收藏