✍️ [阅读笔记] An Overview of Federated Deep Learning Privacy Attacks and Defensive Strategies
本文是一篇关于联邦学习的隐私攻击和防御策略的综述文章,作者2020年挂在CoRR上。
🙋♂️张同学 📧zhangruiyuan@zju.edu.cn 有问题请联系我~
这里是目录呀~
- ✍️ [阅读笔记] An Overview of Federated Deep Learning Privacy Attacks and Defensive Strategies
- 🌵 艺、Introduction
- 🎄 尔、威胁模型😈 Threat Model
- 🌲 伞、攻击方法👹 Attack Methods
- 🌳 寺、防御措施⛑ Defensive Measures
- A. 🐭 梯度子集(Gradient subset)
- B. 🐮 梯度压缩(Gradient compression)
- C. 🐯 Dropout
- D. 🐰 差分隐私(Differential privacy)
- E. 🐲 安全多方计算(Secure multiparty computation(SMC))
- F. 🐍 同态加密(Homomorphic encryption)
- G.🐴 鲁棒性聚合(Robust aggregation)
- 🌴 舞、Related Work
- 🌱 柳、Conclusion
- 🌿 悟:我的获悉
本文的主要贡献如下:
-
对FL的隐私进行的攻击方法进行总结、分类。
In this paper, we analyze existing vulnerabilities of FL and subsequently perform a literature review of the possible attack methods targeting FL privacy protection capabilities. These attack methods are then categorized by a basic taxonomy.
-
对防御策略进行总结、分类。
Additionally, we provide a literature study of the most recent defensive strategies and algorithms for FL aimed to overcome these attacks. These defensive strategies are categorized by their respective underlying defense principle.
The paper concludes that the application of a single defensive strategy is not enough to provide adequate protection to all available attack methods.
🌵 艺、Introduction
联邦学习背景介绍略过。
👽 已经通过大量研究表明,联邦学习的隐私保护能力存在漏洞:
However, recent research has shown multiple vulnerabilities in the privacy protection capabilities of FL [13]–[24]. These attack methods cast a shadow on the applicability of FL for privacy-sensitive information.
🎄 尔、威胁模型😈 Threat Model
A. 🐭 攻击面(Attack surface)
应该指的是
敌方的攻击范围
恶意节点的攻击一般有下列目标:
-
解析客户端隐私数据
First and foremost is to extract private information from victim clients.
-
强迫模型以不同于预期的表现的方式运行
A second goal is to purposefully force the model to behave differently than intended.
-
引入后门(introducing backdoors)
-
诱导错误分类(inducing missclassification)
-
使模型无法工作(rendering the model unusable)
-
恶意服务器的攻击范围:
-
向客户端发送自定义模型
The ability to adapt the model sent to all clients and/or ability to determine and regulate the participating clients. Furthermore, the server can send custom models to targeted clients.
-
The ability to differentiate the model updates from clients before aggregation.
看不太懂呀,emmm
-
聚和服务器知道了聚和的模型中的内容
这里是假设在安全聚和的场景下吧?
The server is knowledgeable of the aggregate model.
恶意客户端的攻击范围:
-
客户端可以访问到已经聚和好的模型
这里应该也是假设了安全聚和的场景吧
The client has access to the aggregate model.
-
操作训练过程中的本地数据
The ability to manipulate the data on which the client trains the model, as well as regulating the training process.
-
能够修改梯度
The ability to manipulate their gradient update.
-
在聚和期间影响模型性能
The ability to influence the impact of their model during aggregation.
B. 🐮 客户端或者服务端的攻击(Client or server-side attacks)
本文假设客户端和服务器之间的通信是安全的,即不考虑通信过程中的泄露信息。但是,这就忽略了一个攻击
中间人攻击,这个敌人假装服务器与客户端通信/假装客户端与服务端通信,所以这个攻击被作者当做了server-side攻击。
In this paper, all communication between the server and the clients is assumed to be secure. Only the clients and server themselves are considered viable points for the execution of attack methods. Therefore, the system is only considered to be vulnerable either on the client-side or the server-side. The one exception to this rule is the man-in-the-middle attack, where an adversary pretends to be a server to the client or/and a client to the server and is therefore in-between the communication. Such an adversary is assumed to have the same threat model as for server-side vulnerabilities.
C. 🐯 黑盒或者白盒攻击(Black-box or white-box attacks)
黑盒、白盒攻击概念:
-
White-box attacks mean that the adversary has complete knowledge of the system except for the private data.
-
白盒举例:FedAvg算法是白盒
In the federated averaging algorithm, the clients are assumed to have a full description of the model and are therefore vulnerable to white-box attacks.
-
-
Blackbox attacks mean that the adversary is limited and is only able to use the system without any detailed knowledge of the inner workings of the system.
-
黑盒举例:
On the server-side, this is also true but recent studies propose models in which the server has no knowledge of the model other than its conception [25]. This might force the server-side attacks towards a black-box scenario.
-
黑盒有可能变成白盒:
In some cases, it is possible to extract information about the systems architecture and thereby force the black-box towards a more white-box threat model. Method such as GPUsnooping can be exploited [26] or model extraction for online services [27].
-
D. 🐰 主动、被动攻击(Active or passive attacks)
主动攻击是指攻击方法依赖于通过调整参数、通信或其他系统属性来操纵系统以达到对抗目标。
这一类攻击影响了工作系统,所以在一般意义上可以被检测出来。
A c t i v e a t t a c k s Active\ attacks Active attacks imply that the attack method relies on manipulating the system by adapting parameters, communication or other system-properties to achieve adversarial goals. Because these types of attack influence the working system they are in a general sense detectable. Active attacks may also be responsible for corruption the system to a point where it is no longer properly functioning.
P a s s i v e a t t a c k s Passive\ attacks Passive attacks imply that the attack method can be performed without the need to adapt any parameters in the system. Since these attack methods leave no trace of their execution, they are generally impossible to detect, which makes them a more dangerous set of attack methods.
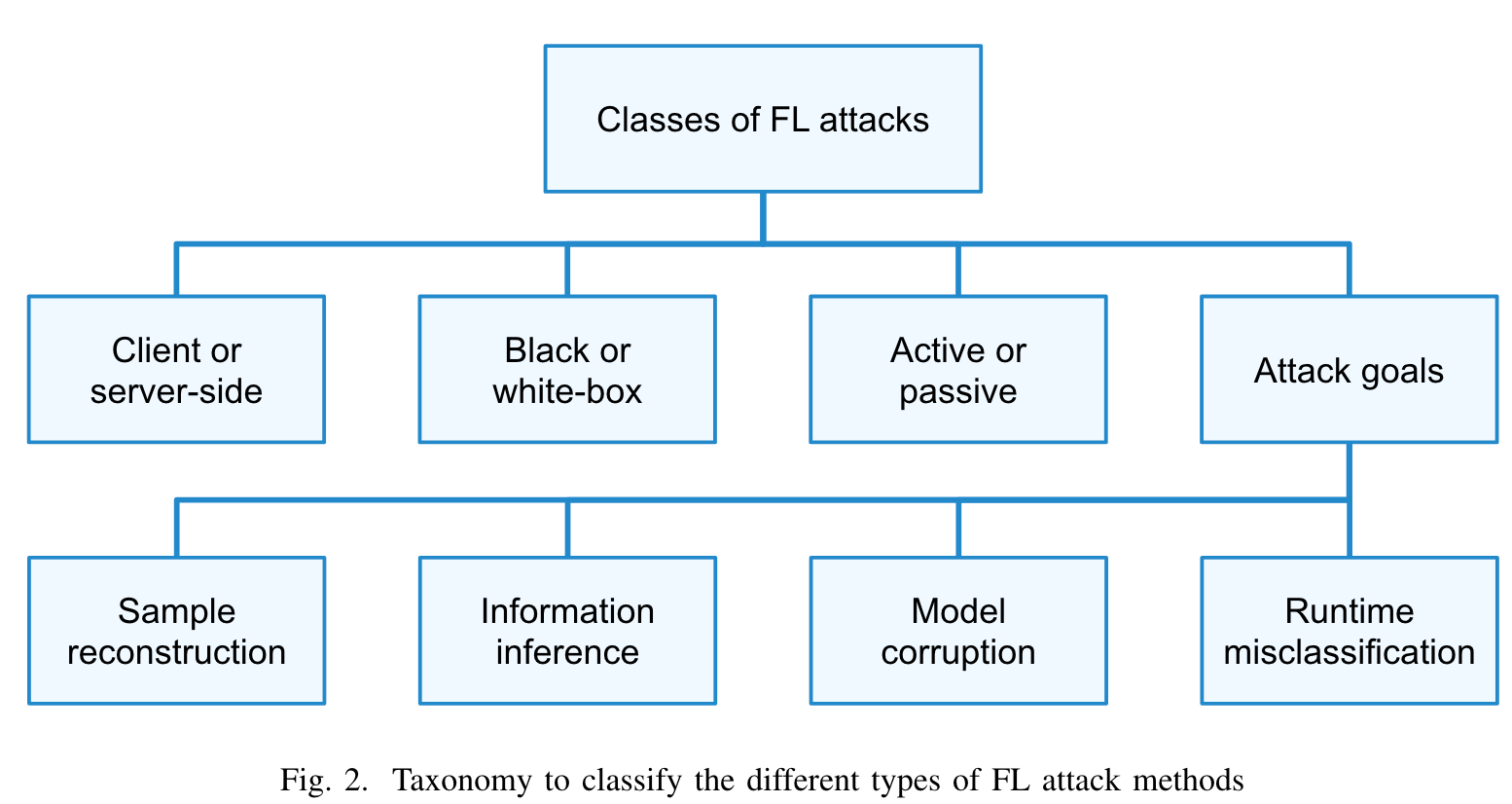
E. 🐲 攻击目标(Attacker goal)
- 样本重建(Sample reconstruction)
重构数据信息
Sample reconstruction aims to objectively reveal what training data was used by the clients. The success of the attacker in achieving this goal can be assessed by comparing the similarity of the reconstruction with the original data. The ability to launch a reliable sample reconstruction attack is the most intrusive concerning private information since it reveals sensitive information in full. If a sample reconstruction attack can be carried out with relative ease by the server or an adversary, the system as a whole may not claim to be privacypreserving.
- 信息推理(Information inference)
推理数据中的信息
Information inference attacks aim to learn private information more speculatively. This information may consist of:
-
Inferring class representatives—This type of inference tries to recreate samples that would not stand out in the original dataset. When successfully creating such samples the adversary can learn a lot about the underlying dataset.
-
Inferring membership (of the sample)—When provided a sample, membership inference tries to accurately determine if this sample has been used for the training of the network.
-
Inferring data properties—This attack tries to infer metacharacteristics of the used dataset (e.g. the data consists of mostly red cars).
-
Inferring samples/labels—This attack aims to accurately recreate (rather than reconstruct) training-samples that were used during the training session and/or associated labels that were used during training.
- 受贿模型(Model corruption)
改变模型,使其对攻击者有利。
Model corruption aims to change the model to the benefit of the attacker. Such attacks can introduce exploitable backdoors in the model or even make the entire model useless. Model corruption attacks are generally not assumed to violate the privacy of participating clients.
- 运行时错误分类(Runtime misclassification)
欺骗模型在运行时产生错误。
Runtime misclassification attacks aim to trick the model into making erroneous predictions during runtime. FL is susceptible to these types of attacks similar to non-distributed ML methods. Generally, runtime misclassification attacks do not violate client privacy directly but may be used to circumvent ML-based security measures.
🌲 伞、攻击方法👹 Attack Methods
本章的内容可以看图展开,若有需要了解某一类型的攻击,可以沿着这一方向进行
Table I lists the attack methods proposed in the literature as well as their characteristics. In the following, we discuss each one of these methods, classified according to their associated attack goals. Table II illustrates the exploited vulnerabilities of the hereafter listed attack methods.
各种攻击方法及特点:


A. 🐭 重现攻击(Attacks targeting reconstruction)
-
Loss-function/ReLu exploitation: Sannai [28] describes a mathematical framework that (given access to a white-box model(白盒攻击)) can determine what relation the input has to a given loss at the output(可以确定输入与输出的给定损失之间的关系,但是这个内容有什么用呢?). It relies on the non-smoothness of the ReLu function and has been argued to work solely on deep neural networks. Due to the use of ReLu activation on each layer, an adversary can compute backwards which nodes were activated. Several polynomials that describe the input-output relation can be formulated and subsequently, these polynomials are used to calculate what training samples are consistent with the loss surface at the output. (可以用几个多项式来描述输入输出关系,然后用这些多项式来计算哪些训练样本与输出处的损失面一致。?是不是这样就可以)
The application domain of this attack method is limited to linear models with incorporated ReLu activation functions. Furthermore, this method is weak against any form of noise due to its strict mathematical nature. Unfortunately, no demonstration is given of the workings of this attack method. -
First dense layer attack: Le Trieu et al. [16] showed mathematically that gradients of a model may in some cases reveal the training data. This attack relies on the fact that the gradients of all weights accumulated in a neuron are scaled linearly to the activation of the prior layer [16], [29]. In the case that a client has trained on a singular sample, this method fully reconstructs this trained sample. (在只有单个样本的训练中,该方法可以对这个样本进行重建)
This attack method is not applicable to recurrent neural networks and requires extra algorithms to be useful in for convolutional networks.(不适合RNN,需要额外的算法才能适应CNN) Furthermore, as the local dataset grows larger the reconstructions that are to be performed with this method will become more unreliable. Still, this remains a very viable attack method due to its ease of use and nearconstant computational cost.
- DLG/iDLG: A recent algorithm called Deep Leakage from Gradients (DLG) describes an optimization algorithm that reproduces the training sample iteratively by optimizing the input to produce the correct gradients for a client. A slight variation to this algorithm also proves to be viable for slightly larger batches of samples [14]. In a follow-up paper, a different research group proposes improved DLG (iDLG) as a more efficient and accurate version of DLG [15]. DLG and iDLG are applicable only when the local dataset of a client is sufficiently small due to the required high computation costs for reliable results on larger batches.
B. 🐮 推理攻击(Attacks targeting inference)
-
Model inversion attacks (MIA): The model inversion attack introduced by Fredrikson et al. [17] works on the premise that the trained linear model is accessible to the adversary in a black-box fashion(黑盒攻击). The adversary may only provide its input and collect the respective output. Also, the adversary has incomplete information about the input and complete information about the output. This data is used to detect correlations between the (still unknown) input variables and the known output values [17]. It does this rather crudely by ’brute forcing’ all variations of unknown input-values to predict the most likely private feature. A practical application is knowing a victim’s personalized outcome of a model, as well as some publicly known features such as age, gender, etc. These features allow the adversary to reasonably predict the missing data.(预测一些年龄、性别特征,并根据这些去更加合理地预测一些数据。)
A follow-up work presents a new version that has a blackbox and white-box applicability [18](延伸的版本支持黑盒、白盒). This white-box attack works by trying to predict the most likely input for a given label. This allows the adversary to reconstruct a generalized input image for a specific label.
The model inversion attack is only applicable in linear models(模型反演攻击只适合线性模型). Furthermore, the authors note that it is often quite easy to come up with models for which this attack method does not work. A big weakness of this attack is that it is computationally infeasible for large input spaces since it in essence brute-forces all input combinations(这种攻击的本质是强迫输入组合,所以在大规模输入下需要大量的计算).
-
mGAN-AI: The multitask GAN for Auxiliary Identification (mGAN-AI) attack relies heavily on the training of GANs to reconstruct accurate approximate training samples(很大程度上依赖GAN来重建样本的细节). This method of attack requires the model updates from each client and an auxiliary dataset. From these updates, a set of fake input images is generated which result in the same update. Then a discriminator network tries to figure out: 1. if these images are fake or real, 2. to which client these images belong, and 3. to which category the images belong.
After some training, the mGAN-AI can provide a revealing reconstruction of training samples belonging to a victim client. In addition to this passive attack, the authors also describe an active variant which works in the same way but ensures that non-clients don not participate. This allows the GAN to optimize its reproduction capabilities towards a targeted victim [19]. Demonstrative results show that this technique is very viable to compromise client-level privacy.(支持主动、被动攻击)
This method of attack is only applicable in cases where clients have mostly homogeneous data and there is an auxiliary dataset available. Since the method relies on generative adversarial networks, this method is only applicable on data which can be synthesized.(mGAN-AI算法有一定的限制:客户端的数据是同分布的、数据是能够通过GAN生成的)
-
GAN: This attack actively targets a victim client to release private data by poisoning the shared model in the adversaries favour.(主动攻击客户端,通过毒害共享模型来释放隐私数据。) In a simple setting, the adversary uses the shared model to differentiate the victim’s model update from which the adversary learns which labels have been used. Then the adversary uses a generative adversarial network (GAN) [30] to generate images for one of the labels exclusively used by the victim. The adversary then purposefully mislabels these images as one of the labels exclusively used by itself. The gradients of the victim will become steeper as the generated and subsequently mislabeled images get more re-presentable as the victim’s images [20].(也就是说,知道了客户端的一张图片,就利用GAN来生成一些数据,并将这个数据标错标签,进而引起客户端的模型抖动)
There is some critique to this attack. Although useful in a controlled environment, this attack method supposes that the victim and adversary share at least one shared label and one exclusive mutual label which is unrealistic as the client pool gets larger(需要对手和客户端至少共享一个相同样本、一个相反样本). Additionally, it is infeasible to distinguish a targeted victim in a practical federated setting due to the randomness of the selected clients and the degradation of influence of the adversary when averaging weights [19](在联邦学习中,因为选择客户端的随机性、平均梯度造成的对手模型的影响力降低,所以有比较大的限制).
C. 🐯 错误分类攻击(Attacks targeting misclassification)
错误分类攻击的行为是生成样本,目的是导致运行时错误分类。这个攻击对于联邦学习来说可能十分有效,比如在设备上进行人脸识别任务等。
Here we discuss only adversarial example attacks as a form of misclassification attacks. Adversarial example attacks aim to produce samples that will be purposefully misclassified at runtime [31], [32]. Federated learning is vulnerable to this because the deployment of the model means that adversaries have virtually no restrictions when crafting adversarial examples. If the intended use of the model is, for example, ondevice authentication (e.g. by means of face recognition) then adversarial example attacks can be very effective.
D. 🐰 模型损坏攻击(Attacks targeting model corruption)
模型中毒(在模型中引入后门)是本节介绍的攻击的一种,在本节中作为典型进行展示。另外还有数据投毒,在文末简单地说了一嘴。
Here we discuss only model poisoning attacks as a form of model corruption attacks. Using this attack method, every client can directly influence the weights of the shared model which means that poisoning the shared model becomes trivial. Model poisoning can be used to introduce a backdoor which can be leveraged by the adversary [21]–[24].
“为啥每个客户端可以直接影响共享的权重,也就意味着毒害共享模型变得微不足道呢?”,这句话是什么意思呀?
A specific attack method designed for FL was demonstrated by Bagdasaryan et al. [22]. The attack poisons the model by exploiting the fact that a client can change the entire shared model by declaring that it has a significantly large amount of samples. This allows a client to change the shared model in order to insert a backdoor. One example use case is forcing a shared model to be biased towards an adversarial label/prediction, such as forcing a word auto-completion model to suggest a brand name, or to force a model to incorrectly classify images of a political figure as inappropriate (后门攻击的案例,之后在写文章的时候可能会用到).
增加样本数量来绕过拜占庭:
Similar work by Bhagoji et al. [33] demonstrate the viability of this method further and show how this attack method can be used in a stealth manner. Furthermore, they demonstrate how to circumvent byzantine-robust aggregation mechanisms [34], [35](还可以使攻击绕过拜占庭聚合机制,所以拜占庭机制是不是也是不安全的呢?). These types of aggregation algorithms are designed specifically to reduce the influence of singular clients.
女巫攻击来绕过拜占庭:
A different approach is taken by Fung et al. [24] where, rather than relying on boosting of sample numbers or gradients, the adversary is capable of joining and leaving different federated clients. This type of attack is called a sybil-based attack [24], [36]. The adversary can then return a multitude of poisoned models back to the server each iteration.
在协作中搞破坏,并造成后果的案例(控制模型发表不当言论的攻击):
Closely related to sybil attacks are joint-effort modelpoisoning attacks. Anecdotal evidence suggests a possible vulnerability for models that train on user input. For example, a twitter chat-bot developed by Microsoft that learned from user communication was corrupted by a coordinated effort of users to post racist and sexist tweets [37].
数据中毒:
指的是对客户端本地的数据投毒,比如切换客户端的标签。但是这样的毒害并不如毒害模型,因为任何可以
毒害数据的方法都可以通过毒害模型实现,因为这些有毒的数据并没有传递到服务端。
In addition to model poisoning attacks, there are also data poisoning attacks. These types of attacks can be successfully used for adversarial goals such as flipping labels [24], [38]. However, it is noted that for FL all data poisoning attacks are inferior to model poisoning attacks for the simple reason that the data is not sent to the server. Therefore, anything that can be achieved with poisonous data is equally viable by poisoning the model [13], [33].
🌳 寺、防御措施⛑ Defensive Measures
-
+ 可靠的有效性
-
~ 受限的有效性
-
- 防御措施几乎完全无效
-
* 上下文相关的有效性(看不懂诶)

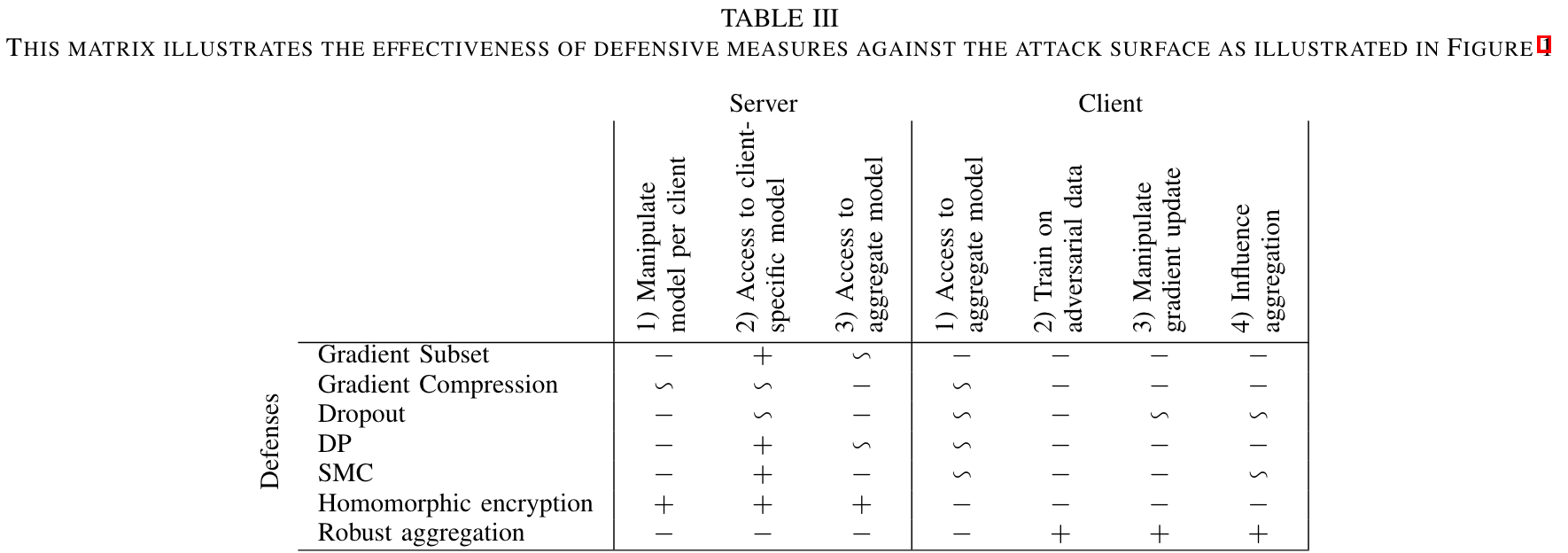
A. 🐭 梯度子集(Gradient subset)
作者认为
梯度子集能防御访问特定客户端的模型攻击?是因为只上传局部梯度信息的原因吗?但是我不认为
梯度子集能防御,我感觉梯度子集并不是局部信息,而是值得上传的信息,这个信息并不是随机的,所以主观上我认为梯度子集并不是一个防御措施。
Initially proposed for the use of Distributed distributed stochastic gradient descent (DSGD), only a subset of all gradients should be communicated to improve communication efficiency [39]. The authors propose a selection method for communicating only the most important gradients as well as adding a randomized weight selection variant. Such a randomized variant is also proposed briefly for a federated setting by [40] for increasing communication efficiency. Yoon et al. [41] proposed a different gradient subset approach and subsequently demonstrated that sending sparse and selective gradients can improve performance for a non-IID dataset.
As a defensive measure, such methods reduce the available information the server has from any client. The incompleteness of such information may cause problems for some attack methods to reliably infer information from the update. However, recent studies show that such methods do not prevent adversaries from inferring reliable information from victims [29], [42](最近的一些研究也证明了梯度子集并不能阻止对手从受害者上推理可靠的信息).
B. 🐮 梯度压缩(Gradient compression)
Although mainly devised for the use of communication efficiency, lossy compression techniques may also be implemented to facilitate some form of information security. Konecny et al. [40] demonstrate how such a method reduces communication costs. The server only has victim specific incomplete information.(作者认为有损压缩能够带来一定程度的安全保障,但是我并不是这样觉得,emmm,这篇有损压缩的文章回头可以看一下)
Other forms of compression are also possible. An autoencoder compressor is proposed to encrypt data transfer [43] in which the server trains an autoencoder on dummy-gradient updates, and subsequently releases the encoding part to each of the clients whilst keeping the decoder part secretive. Every gradient update from each client is now encoded before transfer to the server and decoded server side. This has a couple of advantages. First, the model is compressed by the encoder which will increase communication efficiency. Second, the encoding and decoding result in some information loss about the gradient update. How well this measure prevents the server from malicious reconstruction remains to be seen(编码和解码的这种方法能提高通信效率,这种方式能导致梯度信息丢失,所以作者认为这样的方式能在一定程度上防御攻击,客观上目前并没有防御的研究。但主观上我觉得emmm应该并不能防御吧).
C. 🐯 Dropout
Dropout的本意是为了防止模型的过拟合。dropout增加了客户端所上传的梯度的随机性,这使得一些需要利用准确梯度来实施攻击的方法失效。这是因为原来的攻击方法可以推断准确梯度,而现在只能推断更加泛化(带有随机性)的梯度的信息。
Another way to try to increase defensiveness is to employ a technique called dropout [44]. Although generally used to prevent over-fitting [45], dropout does introduce a certain (finite) randomness to the gradient updates. Training on a set of data-points will not have a deterministic gradient update associated with it, which reduces the exploitable attack surface. Due to the feature-generalizing nature of dropout, it could have an adverse effect if the goal is to infer generalized data rather than exact information. This was demonstrated by [42].
D. 🐰 差分隐私(Differential privacy)
Differential privacy [46] aims to ensure privacy mathematically by introducing noise to variables in the system. DP is often regarded as one of the strongest privacy standards since it provides rigorous provability of privacy(差分隐私是一个可验证的隐私哟~,这是不是也是这玩意最近这么火的原因呀,但是这玩意不就是一个随机数的内容,而且还会影响共享模型的性能).
差分隐私的背景,在很多机器学习应用中成功应用:
DP has been successfully implemented on machine learning applications such as linear regression [47], SVM’s [48], and deep learning [49], [50]. One method to achieve this is to perturb the model before the optimization step in the learning algorithm [51]. Others apply the perturbation at different stages of the SGD algorithm [50], [52].
在联邦学习中实现差分隐私存在着下面这些挑战:
However, it is challenging to implement DP in an FL context. DP works best when each client has access to a significantly large dataset [52]. Since the available data can vary in size between clients, the DP sensitivity should be considered on a per-client basis.
差分隐私方法的使用案例:
Bonawitz et al. [53] proposed a DP implementation for federated averaging for an LSTM language model by clipping gradient updates and adding the noise at the server-side. This ensures that clients cannot infer or attack other clients but may not guarantee safety against server-side attacks. Geyer et al. [54] expanded on this work by implementing FL with DP on an image recognition network. Triastcyn et al. [55] demonstrated FL with Bayesian DP which may provide faster convergence in setting where the data is similarly distributed over participating clients. Bayesian DP leverages this distribution to justify lesser noise amplitude while still retaining the same or even tighter privacy bounds.
E. 🐲 安全多方计算(Secure multiparty computation(SMC))
Secure multiparty computation schemes are algorithms that allow two or more participants to jointly compute functions over their collective data without disclosing any data to the other party. Using such methods to securely aggregate the gradient models from individual clients can be used to shield clients from the server.
安全两方计算常常被用在joined machine learning,为了适应联邦学习,需要两个去信任的服务器链接一些或所有参与的客户端:
Common SMC schemes are developed for the use in secure two-party computation in which there are only two communicating/computing entities. Such schemes have also been developed for the use of joined machine learning [56][59]. In terms of federated learning, this often requires two untrusting servers that connect to some or all the participating clients.
安全三方计算方法也被提出,这些方法依靠至少半数或者大多数参与者诚实:
Other than two-party computation, three-party communication have been proposed as-well [60]–[63]. These methods rely on at least semi-honest participants or an honest majority. Mohassel et al. [60] proposed a novel solution in which three servers use SMC to compute ML-model aggregates. They additionally hint towards a structure in which the clients are subdivided and represented by different servers. If the server is to be trusted, such a structure can even be extended to a hierarchical structure in which a server represents several underlying servers.
为了避免服务器推断受害者客户端的信息,在联邦学习中使用安全多方计算哟~:
For federated learning, one key weakness is that the server can know exactly a specific clients gradient update and thereby might infer information about a targeted victim client. Bonawitz et al. [64] proposed a combination of several protocols to ensure security in a practical federated setting through obscuring the aggregation from the server
F. 🐍 同态加密(Homomorphic encryption)
同态加密算法介绍:
Homomorphic encryption relies on a mathematical encryption method in which mathematical operations applied on an encrypted message result in the same mathematical operation being applied to the original message when the message is decrypted. Using homomorphic encryption in federated learning theoretically ensures no performance loss in terms of model convergence [29].
Homomorphic encryption comes in three forms: Partially Homomorphic Encryption (PHE) which allow only a single type of operation. Somewhat Homomorphic Encryption (SWHE) which allow multiple mathematical operations for only a bounded number of applications. Fully Homomorphic Encryption (FHE) which allows unlimited amounts of operations without restriction [65].
将同态加密算法应用到联邦学习中,保护客户端的数据隐私(医疗数据):
Homomorphic encryption is especially suitable for ensuring privacy against an untrustworthy server. Such a method was proposed by [16] to secure DSGD but may easily be adapted to work on federated averaging. Homomorphic encryption has been proposed as a means to ensure privacy for medical data as-well [66]–[68]. Dowlin et al. [69] proposed an implementation for learning on encrypted data with so-called cryptonets. Phong et al. demonstrated a simple yet effective additive homomorphic scheme for federated learning [29].
使用同态加密来加密数据,并允许中央服务器对加密数据进行训练:
Other collaborative learning strategies include the use of homomorphic encryption to encrypt data and allow a centralized server to train on this encrypted data [70], [71]
同态加密算法的缺点:
Homomorphic encryption does have some major drawbacks that are especially relevant for large scale implementation.
- (全同态需要大量计算开销)First, practically viable fully homomorphic encryption such as FHE generally has large computation overhead which often makes its implementation impractical [59], [65], [68].
- (加密数据大小线性增加,严重影响通信代价)Second, for SWHE the data-size of the encrypted models increase linearly with each homomorphic operation [65]. Thus the encrypted models are notably larger than the plain model, thereby increasing communication costs.
- (客户端的随机加入可能会影响系统安全性)Third, homomorphic encryption requires communication between participating clients to facilitate key-sharing protocols. Communication between clients is not desired in FL and this also introduces a possible vulnerability if new clients should be able to join in-between training rounds.
- (客户端相互勾结)Fourth, without additional safeguards, homomorphic encryption is still vulnerable to all client-side attacks. Additionally, problems may arise for the evaluation of the model.
- 这句话看不懂呀,emmm,哪个大佬给我讲讲。 Lastly, it should be noted that the server in a proper homomorphic scheme does not have direct access to the jointly trained model, which is (generally) the reason for the server to do FL in the first place.
G.🐴 鲁棒性聚合(Robust aggregation)
为什么不能使用平均聚合?:
In the regular FL setting [2] a client sends the newly trained model as well as the number of samples it has back to the server. Since the client can alter these values more robust aggregation methods are required that prohibit malicious clients from exploiting the weighted averaging approach (in which the weights are determined by clients local data size). Furthermore, multiple clients may work together to conceal their malicious efforts. The centralized server has no way of knowing which of the clients are malicious. This is often revered to as problems involving Byzantine clients [72].
鲁棒性聚合案例:
Blanchard et al. [34] addressed this problem by proposing an aggregation rule called Krum which minimizes the sum of squared distances over the model updates. Effectively removing outliers that are supposedly provided by byzantine clients. Hereby the aggregation is secure against at most less than n − 2 2 \frac{n-2}2 2n−2 byzantine workers among n clients. Although this method is exploitable still [73].
El Mhamdi et al. [73] proposed a byzantine–resilient aggregation rule which is to be used in combination with other rules named Bulyan for the use in DSGD. Hereby the aggregation is secure against at most n − 3 4 \frac{n-3}4 4n−3 byzantine workers among n clients.
针对异构数据:
Li et al. [74] proposed a weighting strategy by reliability for the use of Heterogeneous Data. (对异构数据进行加权处理)The ’source reliability’ is determined by calculating the distance between the clients’ update and the aggregate update.
Pilluta et al. [75] proposed an approximate geometric median (采用中值聚合)for the use in federated learning and demonstrated its effectiveness by introducing model corrupting updates and data. The results demonstrate only a substantial robustness improvement for linear models.(对线性模型具有较好的鲁棒性)
Harry Hsu et al. [76] proposed a server-side momentum implementation(服务端动量,会大大地降低恶意客户端的影响) specifically for the use of non-IID client datasets. Combined with the random client selection native to federated learning [2] this may greatly reduce the influence a malicious client has over a multitude of rounds.
一种依赖公共数据集实现的联合学习,而不是共享的模型,(但是我不太懂,都有一个公共的数据集了,还有联邦学习的意义吗?) :
Chang et al. [25] devised a clever knowledge-sharing algorithm for robust privacy-preserving, and heterogeneous federated learning named Cronus. Their algorithm relies on a publicly available dataset known to all clients. Instead of sending model updates, participating clients send their predicted labels from the publicly available samples. Their subsequent aggregation uses the robust mean estimation [77] algorithm which is specifically developed or high dimensional robust aggregation. Hereafter the aggregated labels are sent to all clients, which subsequently use these labels to update their local model. Cronus has been demonstrated to be consistently robust against basic model poisoning strategies at the cost of model accuracy.
🌴 舞、Related Work
其他相关的攻防相关的综述
There is a small number of papers available that discuss different attack methods and defensive strategies for FL models. A recent survey paper [13] only lists attack methods and assesses their value on the implementation method of the federated algorithm. Other works on federated learning such as [78], [79] list various defensive strategies but are more focused on implementation and application consideration of FL. Xu et al. [80] provides a taxonomy by which to list defensive strategies and subsequently shows a small number of defensive strategies categorized. Kairouz et al. [81] provide an elaborate description of open problems in FL. These problems are accompanied by a detailed description of privacy concerns in terms of exploitable vulnerabilities and defenses.
🌱 柳、Conclusion
This paper discussed the basic principles of FL and showed multiple vulnerabilities FL has to insider attacks. A client cannot assume that data privacy is preserved since the centralized server can exploit these vulnerabilities to obtain information about private client data. At the same time, several securityenhancing strategies can be implemented. Some of which provide a mathematical proof of privacy preservation whilst others show their effectiveness towards a specific attacking strategy. The paper further lists the attack methods found in the literature. These attacks are classified using several characteristics: the source of attack, active and passive attacks, white-box or black-box viability, the attacker’s goal, and further restrictions. Furthermore, defensive measures are listed by their underlying principle. An easy to use matrix is illustrated that provides a rudimentary evaluation of the effectiveness of defensive methods against attack strategies.
🌿 悟:我的获悉
本文的主要贡献是什么?
本文的核心难点在哪里?
- 综述性文章要求作者具有大量的文献阅读量、总结、整理文献的能力。
本文的哪些地方可以进行改进?
-
本文寻找到的这些防御措施案例很多并不是为了解决攻击问题,而是为了解决数据非独立同分布、通信效率、提高协作效率等问题。这可能与防御这个方向的文章较少有关系。
-
比如下面的这个案例
Harry Hsu et al. [76] proposed a server-side momentum implementation(服务端动量,会大大地降低恶意客户端的影响) specifically for the use of non-IID client datasets. Combined with the random client selection native to federated learning [2] this may greatly reduce the influence a malicious client has over a multitude of rounds.
-
这项研究是为了解决non-IID问题的,感觉并不是为了解决防御问题,而且这种算法也没有进行防范攻击的实验,所以我主观上感觉案例寻找较差。
-
-
阅读第「舞」章可以看出,已经有相关的攻击综述类文章,本文的创新点在于补充了防御类的文献,但防御类文章的内容不是很够,所以本文的创新点较低,所以这是不是也只能挂在CoRR上的原因呀。
-
以后若做这一项工作,可以加上攻击检测类的文章。
-
区块链为区块链带来了存证的作用,我觉得也应该加入到联邦学习攻防上。
你在未来的工作中会用到本文的哪些东西?